review-Extract-Me-If-You-Can-Abusing-PDF-Parsers-in-Malware-Detectors
Review of Extract Me If You Can: Abusing PDF Parsers in Malware Detectors
| <- Go back | Italian Version -> |
Introduction
This repository provides an analysis of the paper Extract Me If You Can: Abusing PDF Parsers in Malware Detectors [1], published in 2016 by Syracuse University.
During the review, a significant error was identified in the algorithm named “Algorithm 1 - Contiguous Memory Operation Identification.” Specifically, the proposed algorithm fails to adequately address the issue discussed, instead introducing an additional vulnerability. The anomaly lies in the lack of proper validation during the grouping process of memory accesses, a critical aspect to ensure that all accesses are handled completely and securely. Such validation is essential for preventing malicious attacks, particularly those known as “address jump” attacks, which exploit fragmented memory accesses to bypass security measures.
The absence of this validation renders the algorithm vulnerable, compromising its ability to effectively identify and mitigate unauthorized access attempts. Consequently, a thorough revision of the algorithm is needed to address this structural weakness. This need is even more pressing given that the proposed attack is presented as a benchmark for cybersecurity, claiming to undermine all existing security systems, while the associated security system is promoted as the only one capable of withstanding it.
Regarding the slides attached to this document, although they are written in Italian, each is described with precision and detail. Thus, the language is not considered a significant barrier to understanding, even for those unfamiliar with Italian. This is especially true since the slides are hurriedly written notes aimed at capturing the idea as it occurred, which may result in errors (e.g., using the same indices for m and g despite referencing two different for each loops, where it would have been more accurate to use separate indices). However, these errors are not reflected in the descriptions provided in this document.
Proposed Functionality
The first essential step in understanding the proposed algorithm in the paper is to analyze its functionality. The algorithm is presented in pseudocode, making it relatively easy to follow. Each element m represents a memory access described by a data structure in the format m = (caller, program_counter, type, data, addr). Consequently, M is an array containing a series of memory accesses.
Similarly, each group of memory accesses is denoted by g, formally defined as g = (start, end, m_list). Here, m_list is a list that includes individual memory accesses, which can be described as [m_start, ..., m_end], where m_start and m_end represent the first and last accesses in the group, respectively.
With this basic information, one can begin to understand the logic and purpose of the proposed algorithm. In essence, the algorithm aims to manage and organize memory accesses into contiguous groups, analyzing each access based on provided parameters and coherently grouping sequential and related accesses. This approach is critical for ensuring efficient and secure memory access management, especially in the context of potential runtime attacks. Below is a screenshot illustrating the algorithm’s implementation in pseudocode.

Observations on the Proposed Algorithm
In the analysis, M represents a list of memory accesses, while WQ is initially an empty list of groups g. The algorithm processes each element m in M through a for each loop, evaluating the type of memory access for each operation.
-
If the memory access is of type
read:-
It checks if there exists a group
ginWQsuch thatg.end + 1equalsm.addrandg.callermatchesm.caller. If true, memory accessmis added to groupgviaExtend(g,m). -
If a group
gexists inWQwherem.addrlies betweeng.startandg.end, groupgis moved to the front of the list viaMove to front. -
If access
mdoes not match any existing group, a new groupgis created withmas the first element, and the group is added to the front ofWQ.
-
-
If the memory access is of type
write:- It checks if there exists a group
ginWQthat containsm. If true, groupgis removed from the listWQ.
- It checks if there exists a group
A more detailed analysis of the algorithm applied to a sequence of memory accesses such as [1, 2, 100, 101, 102, ..., 999, 1000, 3, 4] demonstrates how the accesses [1, 2] and [3, 4] are included in a single group, named g1, while a second group is formed by the accesses starting at 100 and ending at 1000. This is also illustrated in the attached visual representation, which clearly shows the separation and organization of groups based on the sequence of memory addresses.
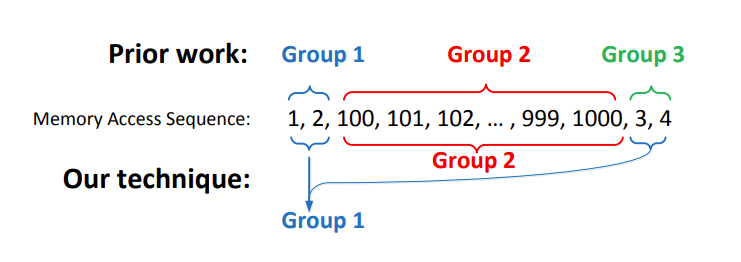
This example highlights how the algorithm dynamically groups memory accesses based on contiguity and sequentiality conditions. However, it also illustrates how specific sequences can influence the structure of the created groups, especially in the presence of large intervals between addresses.
What would happen, though, if this algorithm were applied to the access sequence [1, 2, 100, 101, 102, ..., 999, 1000, 4, 3]- replacing memory access 4 with memory access 3? Let’s review the conditions of the algorithm together…
First Iteration
m_i = 1;
WQ = [];
g_j = null;
// g_j.end +1 == m_i.addr // FALSE -> g_j doesn't exist
// g_j.start <= m_i.addr <= g_j.end // FALSE -> g_j doesn't exist
create_new_group(m_i) // so g_a now exist and it contains just m_i, so [1]
Second Iteration
m_i = 2;
WQ = [g_a];
g_a = [1];
g_j = g_a;
g_j.end +1 == m_i.addr // TRUE -> 1 + 1 == 2
g_j.add(m_i) // so now g_a is equals to [1, 2]

Third Iteration
m_i = 100;
WQ = [g_a];
g_a = [1, 2];
g_j = g_a;
// g_j.end +1 == m_i.addr // FALSE -> 2 + 1 != 100
// g_j.start <= m_i.addr <= g_j.end // FALSE -> 2, the end of the group g_j, is less than 100
create_new_group(m_i) // so g_b now exist and it contains just m_i, so [100]
// ...
// Iterations ranging from m_i1 = 101 to m_in = 1000
// ...
1002rd Iteration
m_i = 4;
WQ = [g_a, g_b];
g_a = [1, 2];
g_b = [100, ..., 1000];
g_j = g_a;
// g_j.end +1 == m_i.addr // FALSE -> 2 + 1 != 4
// g_j.start <= m_i.addr <= g_j.end // FALSE -> 2, the end of the group g_j, is less than 4
g_j = g_b;
// g_j.end +1 == m_i.addr // FALSE -> 1000 + 1 != 4
// g_j.start <= m_i.addr <= g_j.end // FALSE -> 100, the start of the group g_j, is greater than 4
create_new_group(m_i) // so g_c now exist and it contains just m_i, so [4]
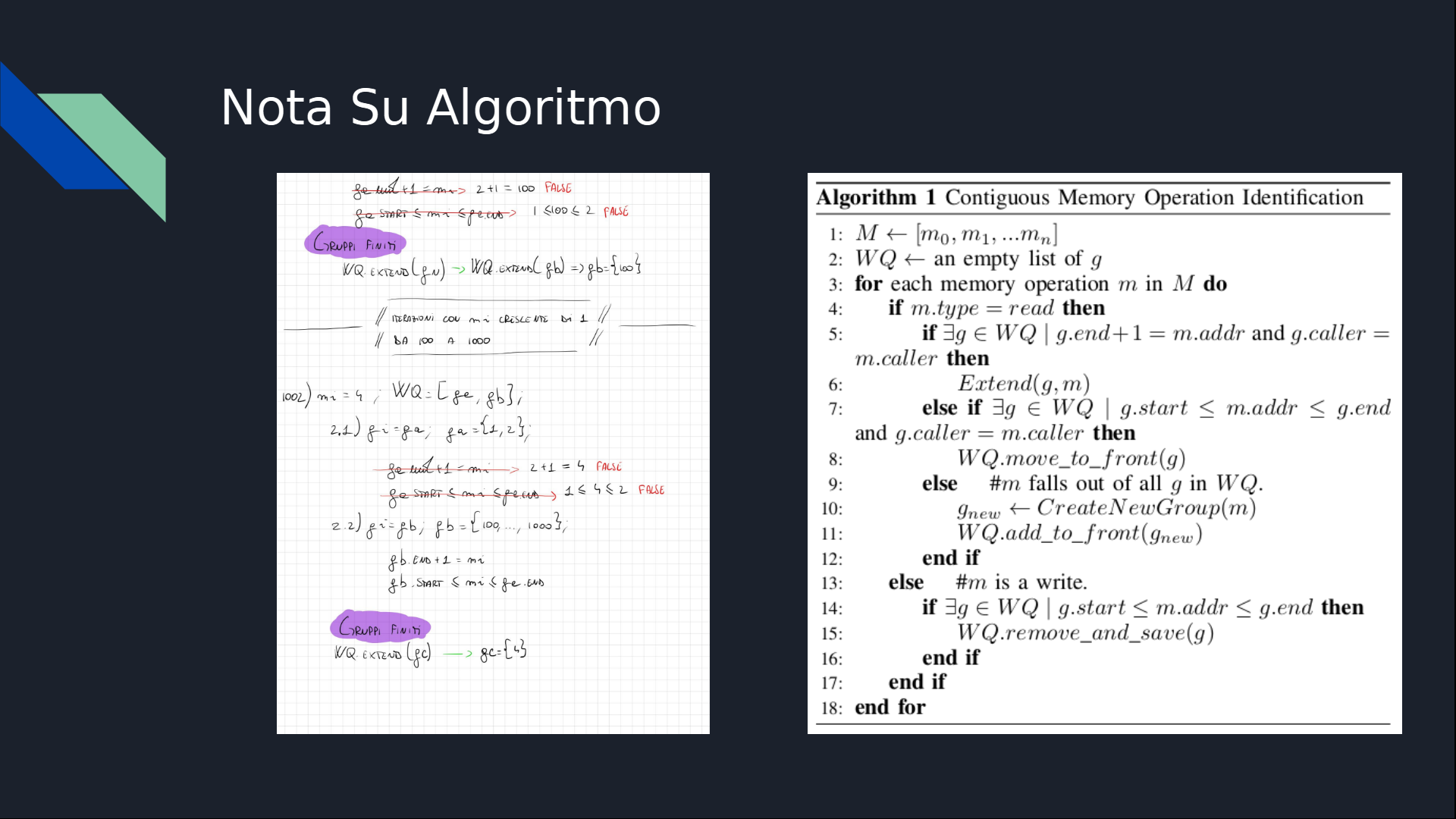
1003rd Iteration
m_i = 3;
WQ = [g_a, g_b, g_c];
g_a = [1, 2];
g_b = [100, ..., 1000];
g_c = [4];
g_j = g_a;
g_j.end +1 == m_i.addr // TRUE -> 2 + 1 == 3
g_j.add(m_i) // so now g_a is equals to [1, 2, 3]
1004rd Iteration - End Algorithm
// The status
WQ = [g_a, g_b, g_c];
g_a = [1, 2, 3];
g_b = [100, ..., 1000];
g_c = [4];
Errors
Inconsistent Validation
Perhaps “inconsistent” is not the most appropriate term, but this validation appears to lack logic. The specific validation under scrutiny is:
g_j.start <= m_i <= g_j.end
This validation is illogical because the extension of a group g_j can only occur if the truth condition g_j.end + 1 == m_i.addr is satisfied. Consequently, it is not possible for a memory access m_i to fall between the start and end of g_j. This would imply the existence of a fractional value between discrete addresses that could make the truth condition described above evaluate to TRUE, which is implausible.
In the context of memory addresses, it is assumed that they follow a discrete order, and memory cells cannot be fractional unless such division is explicitly defined beforehand. In that case, the concept of 1 would need to be redefined, as it might no longer represent an integer but rather a floating-point value. This would necessitate a different definition of memory cell sequentiality compared to the standard interpretation.
Therefore, this validation is unnecessary, and removing it could significantly reduce the algorithm’s complexity since this operation is performed for each m_i in M and for each g_j in WQ.
This Algorithm Does Not Address Its Intended Problem
The algorithm in question was designed to group memory accesses to prevent runtime attacks that may occur through address-jump strategies. The primary goal is to avoid the fragmentation of access groups so that they can be consolidated and analyzed as a whole. This reduces the risk of analyzing potentially malicious code in isolated fragments rather than in its entirety, thereby preserving the effectiveness of the analysis.
However, as demonstrated with a very simple example closely related to the one presented in the paper, this rule can be violated with relative ease. The issue lies in a significant bug intrinsic to the algorithm: its vulnerability to targeted exploits. Once the logic on which the algorithm is based is understood, it becomes possible to design an attack that bypasses the validation. This constitutes a critical flaw that diminishes the algorithm’s effectiveness in preventing attacks, highlighting the need for a revision to enhance the robustness of the protection system.
The solution
As with any self-respecting challenge, there is a viable solution that can mitigate the effects discussed above. It is important to point out that the proposed solution is purely theoretical in nature, since, to the best of our knowledge, the source code for the mitigation, mentioned several times in the paper, has not been made public. This limitation has prevented direct verification of the implemented solution, forcing us to adopt the writing style and conceptual approach outlined by the paper’s authors to extend and complete this thesis.
The absence of the code makes an empirical evaluation of the mitigation impossible, which is a significant limitation, as publication of the code would have allowed for a broader independent analysis and verification. Nevertheless, a theoretical solution consistent with the guidelines outlined by the authors has been formulated, but it remains desirable that the code eventually be made available to allow for further technical investigation and confirmation.
The solution involves inserting a check after the first for each of the algorithm for the join groups.
for k in WQ:
if ∃ h ∈ WQ | k.end+1 = h.start:
k.merge_group(h)
end_if
end_for
Before the application of this solution, the state of the variables at the end of execution is as follows:
// The status
WQ = [g_a, g_b, g_c];
g_a = [1, 2, 3];
g_b = [100, ..., 1000];
g_c = [4];
Whereas, by applying this mitigation you can see clear improvements as the new solution is as follows:
// The status
WQ = [g_a, g_b];
g_a = [1, 2, 3, 4];
g_b = [100, ..., 1000];
Since
1004rd Iteration
// We are out of the first for each
WQ = [g_a, g_b, g_c];
g_a = [1, 2, 3];
g_b = [100, ..., 1000];
g_c = [4];
g_k = g_a;
g_h = g_c;
g_k.end +1 == g_h.start // TRUE -> g_a = [1, 2, 3, 4]; g_c deleted;
If the control cannot be executed outside the for each loop, as it is designed to run at runtime, it becomes reasonable to consider the option of performing group merge whenever a pre-existing group is extended. Thus, when a group, e.g. g_b, is extended to g_b = [1, 2, 3], the proposed control could be triggered by allowing merge between groups g_b and g_c, thus consolidating memory accesses into a single group.


This operation, while increasing computational complexity, is plausible. Even if complexity increases, this increase can be partially offset by the elimination of superfluous or redundant controls, thus improving the overall efficiency of the system. Consequently, the introduction of dynamic group fusion could be an acceptable trade-off between complexity and performance, especially if balanced by targeted optimizations.
Links
[1] https://www.cs.ucr.edu/~heng/pubs/pdfmalware_ndss16.pdf
| <- Go back | Italian Version -> |