review-Extract-Me-If-You-Can-Abusing-PDF-Parsers-in-Malware-Detectors
Review di Extract Me If You Can:Abusing PDF Parsers in Malware Detectors
| <- Go back | English Version -> |
Introduzione
Questo repository contiene la descrizione di una considerazione in merito al paper Extract Me If You Can:Abusing PDF Parsers in Malware Detectors [1], pubblicato nel 2016 dalla Syracuse University.
Durante la revisione del paper, è emerso un errore significativo nell’algoritmo denominato “Algorithm 1 - Contiguous Memory Operation Identification”. In particolare, l’algoritmo proposto non riesce a mitigare adeguatamente l’errore discusso, introducendo invece una vulnerabilità aggiuntiva. L’anomalia riscontrata riguarda l’assenza di un controllo adeguato nel processo di raggruppamento degli accessi alla memoria, aspetto fondamentale per garantire che tutti gli accessi siano gestiti in modo completo e sicuro. Questo controllo è cruciale per prevenire attacchi malevoli, specialmente quelli noti come “salto tra indirizzi”, i quali sfruttano la frammentazione degli accessi alla memoria per aggirare le misure di sicurezza.
La mancata implementazione di tale controllo rende l’algoritmo vulnerabile e compromette la sua capacità di identificare e mitigare efficacemente tentativi di accesso non autorizzato. Di conseguenza, si evidenzia la necessità di una revisione approfondita dell’algoritmo al fine di eliminare questa debolezza strutturale. Anche perché l’attacco proposto viene divulgato come baluardo della sicurezza informatica capace di scalfire qualunque sistema di sicurezza esistente e il relativo sistema di sicurezza come unico sistema capace di resistervi.
In merito alle diapositive allegate a questo documento, benché siano redatte in lingua italiana, ciascuna di esse è descritta con precisione e dettaglio. Pertanto, si ritiene che la lingua non costituisca una barriera significativa alla comprensione, anche per chi non ha familiarità con l’italiano. Anche perché si tratta di appunti scritti di corsa per non perdere l’idea che mi è venuta in mente e quindi potreste trovare degli errori (come ad esempio utilizzare gli stessi indici per m e g seppure facevo riferimento a due for each differenti e quindi in realtà sarebbe stato più corretto utilizzarne due differenti) che invece non ho riportato nelle descrizioni presenti in questo documento.
Il Funzionamento Proposto
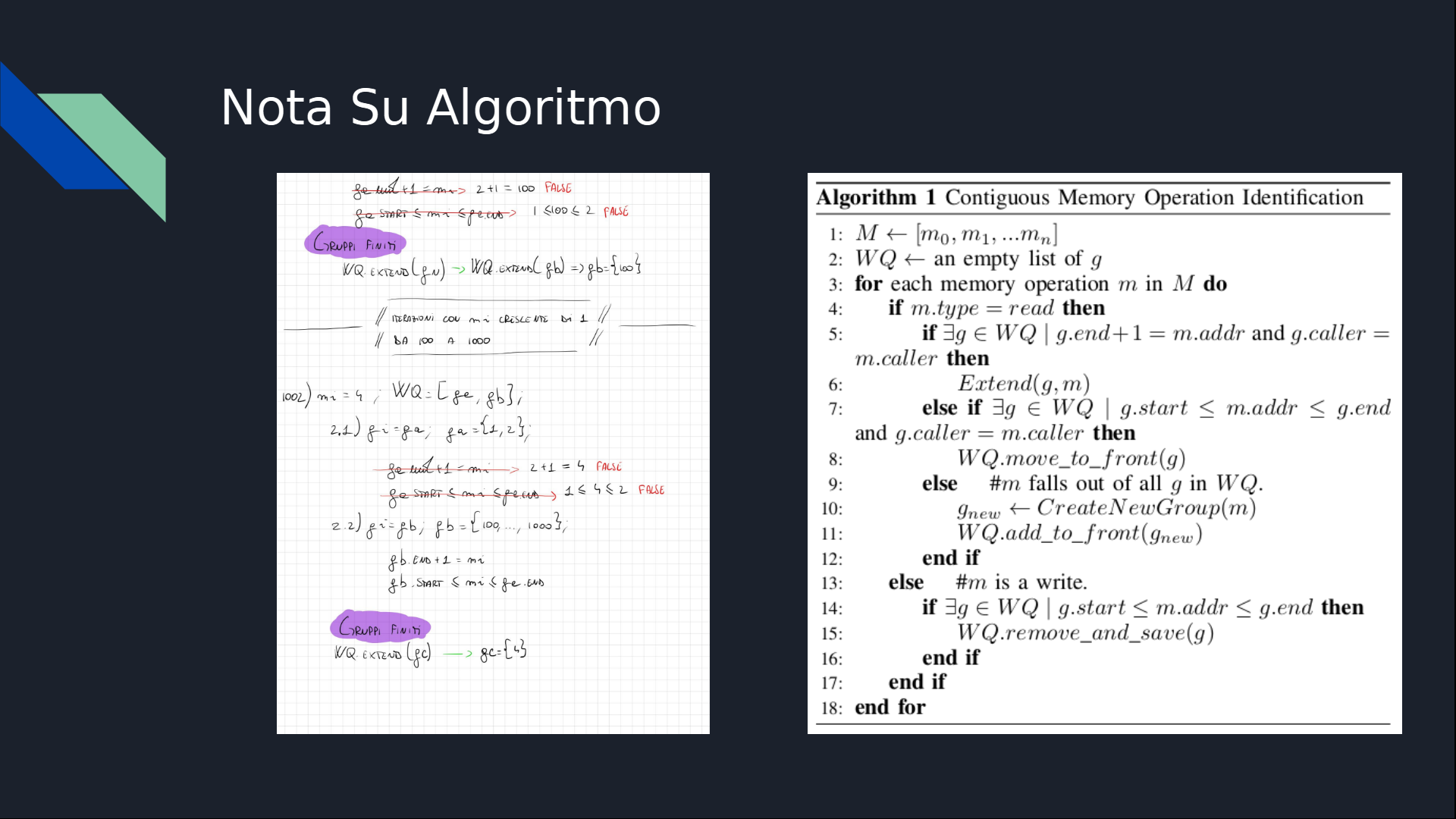
Il primo passo fondamentale per comprendere l’algoritmo proposto nel paper è analizzarne il funzionamento. L’algoritmo è stato scritto in pseudo-codice, risultando di facile intuizione. Ogni elemento m rappresenta un accesso alla memoria, descritto attraverso una struttura dati con il formato m = (caller, program_counter, type, data, addr). Pertanto, M è un array che contiene una serie di accessi alla memoria.
Parallelamente, ogni gruppo di accessi alla memoria viene indicato con g, formalmente definito come g = (start, end, m_list). In questo caso, m_list è una lista che include gli accessi individuali alla memoria, la cui struttura interna può essere descritta come [m_start, ..., m_end], dove m_start e m_end rappresentano rispettivamente il primo e l’ultimo accesso nel gruppo.
Con queste informazioni di base, è possibile iniziare a comprendere la logica e lo scopo dell’algoritmo proposto. In sintesi, l’algoritmo mira a gestire e organizzare gli accessi alla memoria in gruppi contigui, analizzando ogni accesso in base ai parametri forniti e raggruppando quelli sequenziali e correlati in modo coerente. Questo approccio è cruciale per garantire una gestione efficiente e sicura degli accessi alla memoria, specialmente nel contesto di potenziali attacchi a “runtime”. Di seguito è riportato uno screenshot che illustra visivamente l’algoritmo e la sua implementazione in pseudocodice.

Nell’analisi dell’algoritmo proposto, si osserva che M rappresenta una lista di accessi alla memoria, mentre WQ è inizialmente una lista vuota di gruppi g. L’algoritmo gestisce ogni elemento m in M attraverso un ciclo for each, valutando il tipo di accesso alla memoria in modo specifico per ogni operazione.
-
Se l’accesso alla memoria è di tipo
read:-
Si verifica se esiste un gruppo
gall’interno diWQtale cheg.end + 1corrisponda am.addreg.callersia uguale am.caller. In tal caso, l’accesso alla memoriamviene aggiunto al gruppogtramite l’operazioneExtend(g,m), che estende il gruppo per includerem. -
Se invece esiste un gruppo
ginWQtale che l’indirizzo dimsia compreso tra il primo e l’ultimo elemento dig, il gruppogviene spostato in testa alla listaWQattraverso l’operazioneMove to front. -
Qualora l’accesso
mnon corrisponda ad alcun gruppo esistente, viene creato un nuovo gruppogche ha come primo elementom, e questo nuovo gruppo viene posizionato in testa aWQ.
-
-
Se l’accesso alla memoria è di tipo
write:- Si verifica se esiste un gruppo
ginWQche contienem. In questo caso, il gruppogviene rimosso dalla listaWQ.
- Si verifica se esiste un gruppo
Un’analisi più dettagliata dell’algoritmo applicato a una sequenza di accessi alla memoria come [1, 2, 100, 101, 102, ..., 999, 1000, 3, 4] permette di dimostrare come gli accessi [1, 2] e [3, 4] vengano inclusi in un unico gruppo, denominato g1, mentre un secondo gruppo sarà formato dagli accessi che iniziano con 100 e terminano con 1000. Ciò è illustrato anche nella rappresentazione visiva allegata, che mostra chiaramente la separazione e l’organizzazione dei gruppi in base alla sequenza degli indirizzi di memoria.
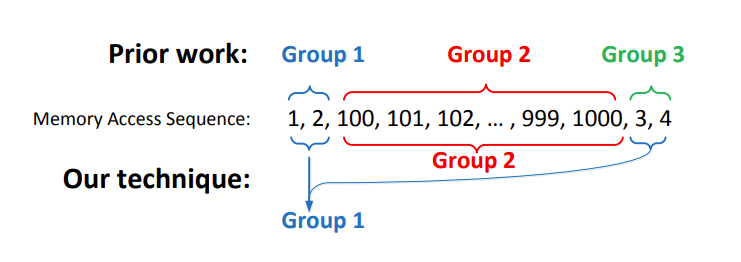
Questo esempio dimostra il funzionamento dell’algoritmo nel raggruppare gli accessi alla memoria in modo dinamico, basato su condizioni di contiguità e sequenzialità, ma evidenzia anche come determinate sequenze possano influenzare la struttura dei gruppi creati, soprattutto in presenza di intervalli molto distanti tra gli indirizzi.
Cosa succederebbe però se si tentasse l’applicazione di questo algoritmo alla serie di accessi [1, 2, 100, 101, 102, ..., 999, 1000, 4, 3]? Ovvero sostituire l’accesso alla memoria 4 con l’accesso alla memoria 3? Vediamolo insieme ripercorrendo le condizioni dell’algoritmo…
Prima iterazione
m_i = 1;
WQ = [];
g_j = null;
// g_j.end +1 == m_i.addr // FALSE -> g_j doesn't exist
// g_j.start <= m_i.addr <= g_j.end // FALSE -> g_j doesn't exist
create_new_group(m_i) // so g_a now exist and it contains just m_i, so [1]
Seconda iterazione
m_i = 2;
WQ = [g_a];
g_a = [1];
g_j = g_a;
g_j.end +1 == m_i.addr // TRUE -> 1 + 1 == 2
g_j.add(m_i) // so now g_a is equals to [1, 2]

Terza iterazione
m_i = 100;
WQ = [g_a];
g_a = [1, 2];
g_j = g_a;
// g_j.end +1 == m_i.addr // FALSE -> 2 + 1 != 100
// g_j.start <= m_i.addr <= g_j.end // FALSE -> 2, the end of the group g_j, is less than 100
create_new_group(m_i) // so g_b now exist and it contains just m_i, so [100]
// ...
// Iterazioni che vanno da m_i1 = 101 fino ad m_in = 1000
// ...
1002 iterazione
m_i = 4;
WQ = [g_a, g_b];
g_a = [1, 2];
g_b = [100, ..., 1000];
g_j = g_a;
// g_j.end +1 == m_i.addr // FALSE -> 2 + 1 != 4
// g_j.start <= m_i.addr <= g_j.end // FALSE -> 2, the end of the group g_j, is less than 4
g_j = g_b;
// g_j.end +1 == m_i.addr // FALSE -> 1000 + 1 != 4
// g_j.start <= m_i.addr <= g_j.end // FALSE -> 100, the start of the group g_j, is greater than 4
create_new_group(m_i) // so g_c now exist and it contains just m_i, so [4]
1003 iterazione
m_i = 3;
WQ = [g_a, g_b, g_c];
g_a = [1, 2];
g_b = [100, ..., 1000];
g_c = [4];
g_j = g_a;
g_j.end +1 == m_i.addr // TRUE -> 2 + 1 == 3
g_j.add(m_i) // so now g_a is equals to [1, 2, 3]
1003 iterazione - Fine Algoritmo
// The status
WQ = [g_a, g_b, g_c];
g_a = [1, 2, 3];
g_b = [100, ..., 1000];
g_c = [4];
Errori
Controllo Inconsistente
Probabilmente inconsistente non è il termine più appropriato ma ad ogni modo questo controllo potrebbe non avere molto senso. Il controllo che si vuole contestare è:
g_j.start <= m_i <= g_j.end
Non è logico eseguire questo controllo, poiché l’estensione di un gruppo g_j può avvenire solo se viene soddisfatta la condizione di verità g_j.end + 1 == m_i.addr. Di conseguenza, non è possibile che esista un accesso alla memoria m_i che si collochi tra l’inizio e la fine di g_j. Questo implicherebbe l’esistenza di una frazione di 1 che possa rendere il controllo di verità sopra descritto verificabile come TRUE, il che non è plausibile.
Nel contesto degli indirizzi di memoria, infatti, si assume l’esistenza di un ordine discreto, e le celle di memoria non possono essere frazionate, a meno che tale frazionamento non sia stato previsto in anticipo. In tal caso, sarebbe stato necessario chiarire meglio il concetto di 1, che potrebbe non rappresentare un valore intero ma piuttosto una variabile di tipo float. Questo implicherebbe una definizione diversa della sequenzialità delle celle di memoria rispetto a quanto generalmente inteso.
Quindi questo controllo non ha senso farlo ed eliminarlo potrebbe permettere di ridurre la complessità dell’algoritmo notevolmente in quanto questa operazione avviene per ogni m_i contenuta in M e per ogni g_j contenuto in WQ.
Questo algoritmo non risolve il problema per il quale nasce
L’algoritmo in questione è stato concepito per raggruppare gli accessi alla memoria al fine di prevenire attacchi runtime che possono verificarsi attraverso strategie di salto tra indirizzi. L’obiettivo principale è dunque quello di evitare la frammentazione dei gruppi di accesso, in modo che essi possano essere riuniti e analizzati nel loro complesso. Ciò consente di ridurre il rischio che l’analisi di un codice potenzialmente malevolo venga effettuata su frammenti isolati anziché sull’intero codice, compromettendo così l’efficacia del controllo.
Tuttavia, come dimostrato con un esempio estremamente semplice e strettamente correlato a quello presentato nel paper, questa regola può essere violata con relativa facilità. Il problema risiede in un bug significativo intrinseco all’algoritmo: la sua vulnerabilità all’uso di exploit mirati. Infatti, una volta compresa la logica su cui si basa, è possibile ideare un attacco che consenta di superare il controllo. Questo rappresenta una falla critica che riduce l’efficacia dell’algoritmo nella prevenzione degli attacchi, evidenziando la necessità di una revisione per migliorare la robustezza del sistema di protezione.
La Soluzione
Come per ogni contestazione che si rispetti esiste una soluzione valida che possa mitigarne gli effetti sopra discussi. È importante precisare che la soluzione proposta è di natura puramente teorica, poiché, a quanto risulta, il codice sorgente per la mitigazione, più volte citato nel paper, non è stato reso pubblico. Questa limitazione ha impedito una verifica diretta della soluzione implementata, costringendo ad adottare lo stile di scrittura e l’approccio concettuale delineato dagli autori del paper per estendere e completare questa tesi.
L’assenza del codice rende impossibile una valutazione empirica della mitigazione, il che costituisce un limite significativo, poiché la pubblicazione del codice avrebbe permesso una più ampia analisi e verifica indipendente. Nonostante ciò, si è proceduto a formulare una soluzione teorica coerente con le linee guida delineate dagli autori, ma rimane auspicabile che il codice venga eventualmente reso disponibile per consentire ulteriori approfondimenti e conferme tecniche.
La soluzione prevede l’inserimento di un controllo dopo il primo for each dell’algoritmo per i unire i gruppi
for k in WQ:
if ∃ h ∈ WQ | k.end+1 = h.start:
k.merge_group(h)
end_if
end_for
Prima dell’applicazione di questa soluzione lo stato delle variabili alla fine dell’esecuzione è il seguente:
// The status
WQ = [g_a, g_b, g_c];
g_a = [1, 2, 3];
g_b = [100, ..., 1000];
g_c = [4];
Mentre, applicando questa mitigazione è possibile vedere netti miglioramenti in quanto la nuova soluzione è quella seguente:
// The status
WQ = [g_a, g_b];
g_a = [1, 2, 3, 4];
g_b = [100, ..., 1000];
In quanto…
1004 iterazione
// We are out of the first for each
WQ = [g_a, g_b, g_c];
g_a = [1, 2, 3];
g_b = [100, ..., 1000];
g_c = [4];
g_k = g_a;
g_h = g_c;
g_k.end +1 == g_h.start // TRUE -> g_a = [1, 2, 3, 4]; g_c deleted;
Se il controllo non può essere eseguito al di fuori del ciclo for each, in quanto concepito per funzionare in runtime, diventa ragionevole considerare l’opzione di effettuare il merge dei gruppi ogni volta che si estende un gruppo preesistente. In tal modo, quando un gruppo, ad esempio g_b, viene esteso a g_b = [1, 2, 3], il controllo proposto potrebbe attivarsi consentendo il merge tra i gruppi g_b e g_c, consolidando così gli accessi alla memoria in un unico gruppo.


Questa operazione, pur aumentando la complessità computazionale, risulta plausibile. Sebbene la complessità aumenti, tale incremento può essere parzialmente compensato eliminando controlli superflui o ridondanti, migliorando così l’efficienza complessiva del sistema. Di conseguenza, l’introduzione del merge dinamico tra i gruppi potrebbe rappresentare un compromesso accettabile tra complessità e prestazioni, soprattutto se bilanciata da ottimizzazioni mirate.
Links
[1] https://www.cs.ucr.edu/~heng/pubs/pdfmalware_ndss16.pdf
| <- Go back | English Version -> |